How To: Convert to Cardinal Wind Directions
Introduction
A wind rose diagram groups wind direction values (normally measured in degrees) into cardinal wind directions and their intermediates points to produce spokes. Therefore, the wind direction values in your raw data needs to grouped into N, NNE, NE, ENE, E and so on.
In order to transform wind direction in degrees into cardinal wind directions you will need to use the VLOOKUP function. In this case VLOOKUP is used to take a wind direction in degrees and return the cardinal wind direction that each value fall under. For example 3 degrees would return “North”.
This requires you to have a database (known as a table_array) which is used as a reference table to return the correct wind direction. For example you may have a prevailing wind of 333 degrees, the VLOOKUP needs to be able to look this value up in the table_array (the index value), it will then take a corresponding cardinal wind direction on the same row as the index value and return it to the cell where you originally created the VLOOKUP function.
This means your table_array needs to contain every possible wind direction value in degrees, as well as the corresponding cardinal wind direction. This is clearly shown in the next section.
Step by Step Process:
1. Create a table_array
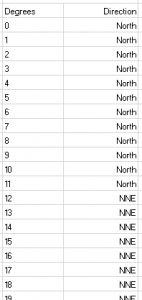 The first thing you will need to do is create your database.This must list – in ascending order – each possible wind directions in degrees and the corresponding cardinal wind speed direction that this should be replaced by. See example:
The first thing you will need to do is create your database.This must list – in ascending order – each possible wind directions in degrees and the corresponding cardinal wind speed direction that this should be replaced by. See example:
2. Create a VLOOKUP Formula
Next you will need to arrange your wind speed data as shown below and and open the VLOOKUP function.
To open the VLOOKUP function click Insert Function on the Formulas tab, in the Insert Function window, search for VLOOKUP, and then click OK.
3. Enter your Function Arguments
Lookup_value
The value to search in the first column of your database. In the example given, the value that needs to be looked up and converted into a cardinal wind direction is contained within cell C3. (The VLOOKUP formula can be dragged down for the rest of the data once the formula has been created)
table_array
The range of cells that contains the data within the database that you have created.
col_index_num
The column number in the table_array argument (your database) from which the matching value must be returned. For example you will col_index_num argument of 2 as the number you want to return is in the second column of your database table.
4. Creating Absolute References for your table_array
In order to be a able to drag the VLOOKUP so that it applies to all of your data, you need to apply absolute references to your table_array.
Dollar signs need to be inserted the letter that refers to the row and the number that refers to the column in the Table see diagram xx
Once you set the absolute cell references for you VLOOKUP formula, click OK and drag this formula down over every row of your raw wind speed table.
5. WRE Web App and WRE v1.7
Please be aware that both the WRE Web App and WRE v1.7 contain inbuilt data sorters. In the case of the WRE Web Application, it will also allow you to locate weather data using an interactive map.